PCA 分析确定主成分后,每一个主成分都是变量的映射,变量有自己的 loading。
PCA Loading
以下是使用 R 进行 PCA 分析并绘制 PCA loading 图的完整代码示例:
示例代码
# 加载必要的包
library(ggplot2)
library(ggrepel)
## Warning: package 'ggrepel' was built under R version 4.3.3
# 加载数据集
data(iris)
# 去掉分类列,仅保留数值列用于 PCA
iris_data = iris[, 1:4]
# 执行 PCA
pca_result = prcomp(iris_data, scale. = TRUE)
# 提取 PCA loading
loadings = as.data.frame(pca_result$rotation)
loadings$Features = rownames(loadings)
# 计算解释度
explained_variance = pca_result$sdev^2 / sum(pca_result$sdev^2)
pc1_label = paste0("PC1 (", round(explained_variance[1] * 100, 1), "%)")
pc2_label = paste0("PC2 (", round(explained_variance[2] * 100, 1), "%)")
# 绘制 PCA loading 图
ggplot(loadings, aes(x = 0, y = 0, xend = PC1, yend = PC2, label = Features)) +
geom_segment(arrow = arrow(length = unit(0.2, "cm")), color = "steelblue", linewidth = 1) +
geom_text_repel(aes(x = PC1, y = PC2), size = 5) +
labs(
title = "PCA Loading Plot",
x = pc1_label,
y = pc2_label
) +
theme_bw()
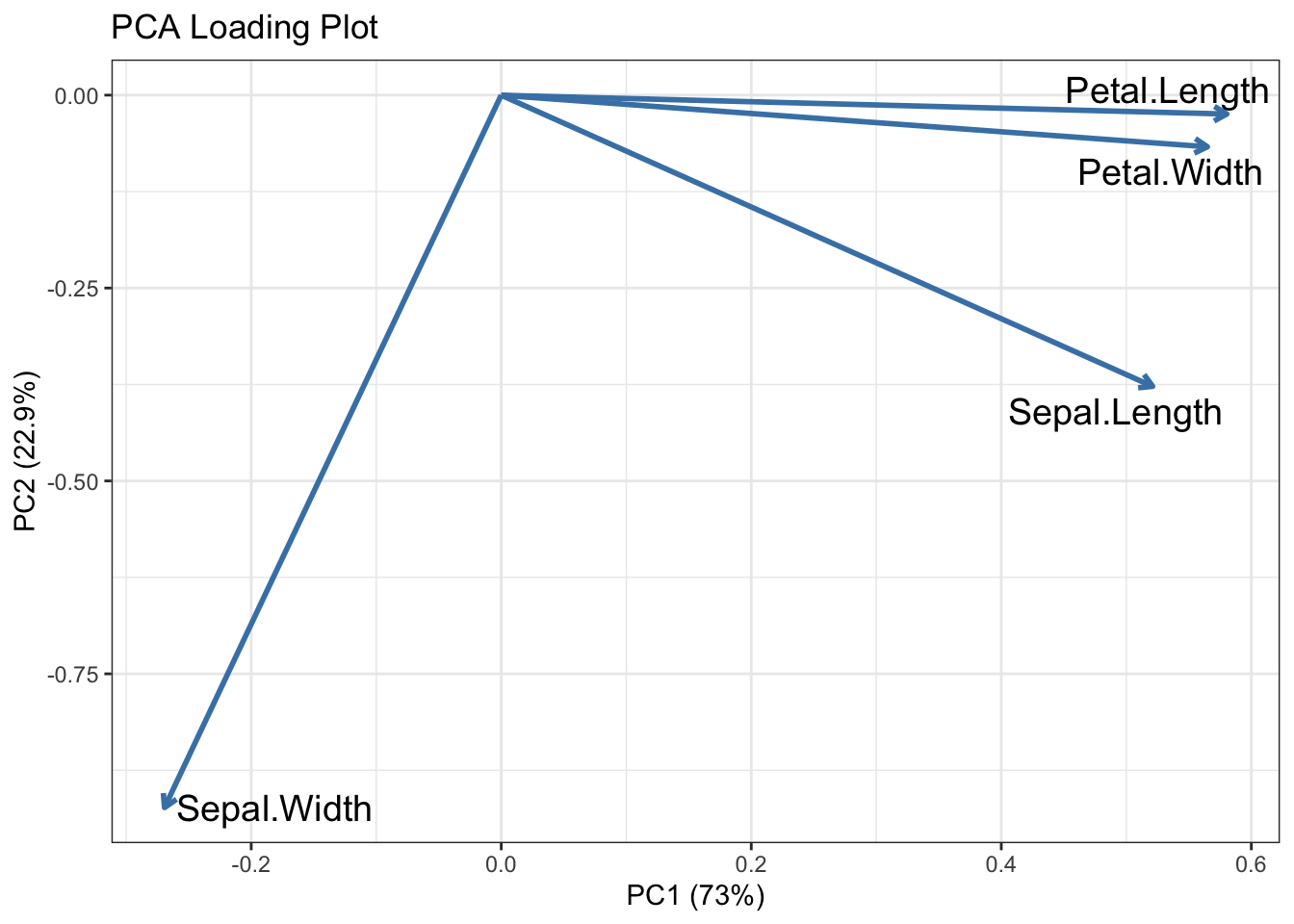
代码说明
-
prcomp方法:- 用于主成分分析。
- 参数
scale. = TRUE标准化数据以消除变量的量纲影响。
-
提取 Loading:
- 使用
pca_result$rotation获取每个变量在各主成分方向的载荷。
- 使用
-
ggplot2绘图:geom_segment用于绘制箭头,表示变量方向和大小。geom_text_repel防止标签重叠。
输出解释
- PCA Loading 图:显示变量在主成分方向上的贡献大小和方向。箭头越长,表示该变量对对应主成分的贡献越大。
- PC1 和 PC2:分别表示第一和第二主成分,可以解释大部分数据的方差。
运行上述代码将生成一个清晰的 PCA loading 图,用于分析变量如何投影到主成分空间中。
PC1 Loading
如果仅需要展示 PC1 上各个指标的 loading,可以将 PCA 的 rotation 数据提取并按降序排列,随后绘制柱状图或条形图来展示。以下是完整的实现代码:
示例代码
# 加载必要的包
library(ggplot2)
# 加载数据集
data(iris)
# 去掉分类列,仅保留数值列用于 PCA
iris_data = iris[, 1:4]
# 执行 PCA
pca_result = prcomp(iris_data, scale. = TRUE)
# 提取 PC1 的 loading 数据
pc1_loadings = pca_result$rotation[, "PC1"]
loading_data = data.frame(Feature = names(pc1_loadings), Loading = pc1_loadings)
# 按 PC1 loading 的绝对值降序排列
loading_data = loading_data[order(abs(loading_data$Loading), decreasing = TRUE), ]
# 绘制柱状图
ggplot(loading_data, aes(x = reorder(Feature, Loading), y = Loading)) +
geom_bar(stat = "identity", fill = "steelblue") +
coord_flip() + # 让柱状图横向展示
labs(
title = "PC1 Loadings",
x = "Features",
y = "Loading Value"
) +
theme_bw()

代码说明
-
提取 PC1 loading:
- 使用
pca_result$rotation[, "PC1"]获取各指标在 PC1 上的载荷。
- 使用
-
排序:
- 按照
abs(Loading)对特征的载荷绝对值进行降序排列,更突出贡献最大的特征。
- 按照
-
ggplot2绘图:- 使用
geom_bar(stat = "identity")绘制柱状图。 - 使用
coord_flip()横向显示,方便阅读长标签。
- 使用
输出结果
- 柱状图:展示 PC1 上各指标的 loading 值,柱状高度和方向表示指标对 PC1 的正负贡献和大小。
- 排序:指标按贡献大小排序,最高贡献的指标排在最上面。
变量数目过多
下面生成了一个包含 100 个变量和 150 个观察值的随机数据框。接下来,使用这个数据进行 PCA 和绘制主成分分析图。
以下是更新后的代码,使用这个随机数据集来进行 PCA 分析,并绘制最重要的 6 个变量的 PCA loading 图:
更新后的代码
# 加载必要的包
library(ggplot2)
library(ggrepel)
library(dplyr)
##
## Attaching package: 'dplyr'
## The following objects are masked from 'package:stats':
##
## filter, lag
## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, union
# 生成随机数据框(100个变量)
set.seed(42)
n_obs = 150
n_vars = 100
random_data = matrix(rnorm(n_obs * n_vars), nrow = n_obs, ncol = n_vars)
colnames(random_data) = paste0("Var", 1:n_vars)
df_random = as.data.frame(random_data)
# 执行 PCA
pca_result = prcomp(df_random, scale. = TRUE)
# 提取 PCA loading
loadings = as.data.frame(pca_result$rotation)
loadings$Features = rownames(loadings)
# 计算解释度
explained_variance = pca_result$sdev^2 / sum(pca_result$sdev^2)
pc1_label = paste0("PC1 (", round(explained_variance[1] * 100, 1), "%)")
pc2_label = paste0("PC2 (", round(explained_variance[2] * 100, 1), "%)")
# 计算 PC1 和 PC2 的 loading 的绝对值
loadings$PC1_abs = abs(loadings$PC1)
loadings$PC2_abs = abs(loadings$PC2)
# 按照 PC1 或 PC2 的 loading 绝对值排序,选择前 6 个变量
top_loadings_pc1 = loadings[order(loadings$PC1_abs, decreasing = TRUE), ][1:10, ]
top_loadings_pc2 = loadings[order(loadings$PC2_abs, decreasing = TRUE), ][1:10, ]
# 合并两个选择的变量,避免重复
top_loadings = bind_rows(list(PC1 = top_loadings_pc1, PC2 = top_loadings_pc2), .id = "id")
# 绘制 PCA loading 图
ggplot(top_loadings, aes(x = 0, y = 0, xend = PC1, yend = PC2, label = Features, color = id)) +
geom_segment(arrow = arrow(length = unit(0.2, "cm")), linewidth = 1, alpha = 1/2) +
geom_text_repel(aes(x = PC1, y = PC2), size = 5, show.legend = FALSE) +
labs(
title = "Top 10 PCA Loading Plot",
x = pc1_label,
y = pc2_label
) +
theme_bw()
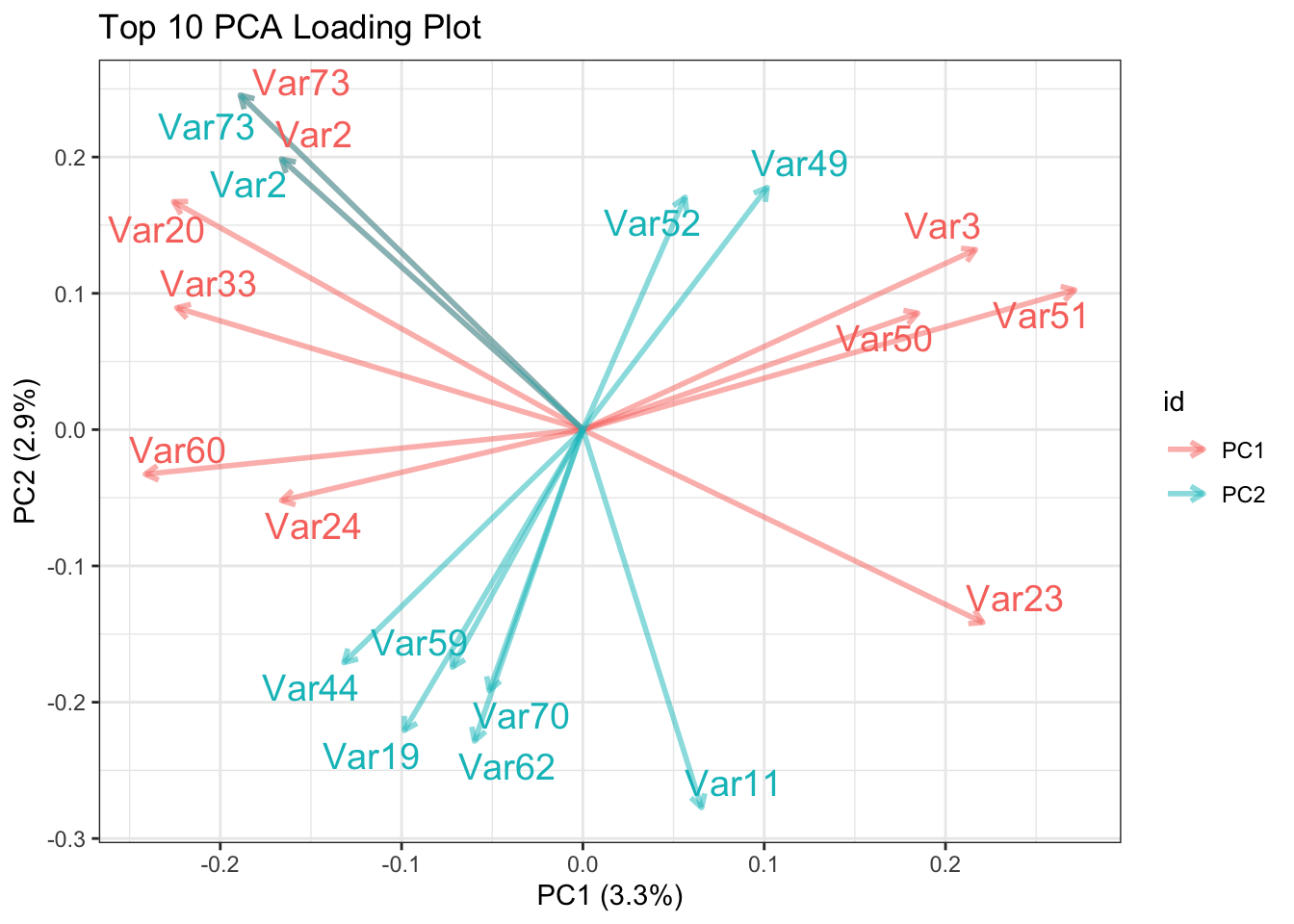
代码解释
- 生成随机数据:使用
matrix(rnorm(...))创建一个 150 行 100 列的矩阵,并将其转换为数据框df_random。 - 执行 PCA:在生成的随机数据框
df_random上执行 PCA。 - 选择最重要的 10 个变量:根据 PC1 和 PC2 的绝对加载值选择最重要的 10 个变量,并绘制它们的箭头。
- 绘制 PCA loading 图:绘制了具有最高加载值的 10 个变量的 PCA loading 图。
您可以运行这段代码以可视化随机数据集中的最重要变量的 PCA loading 图。