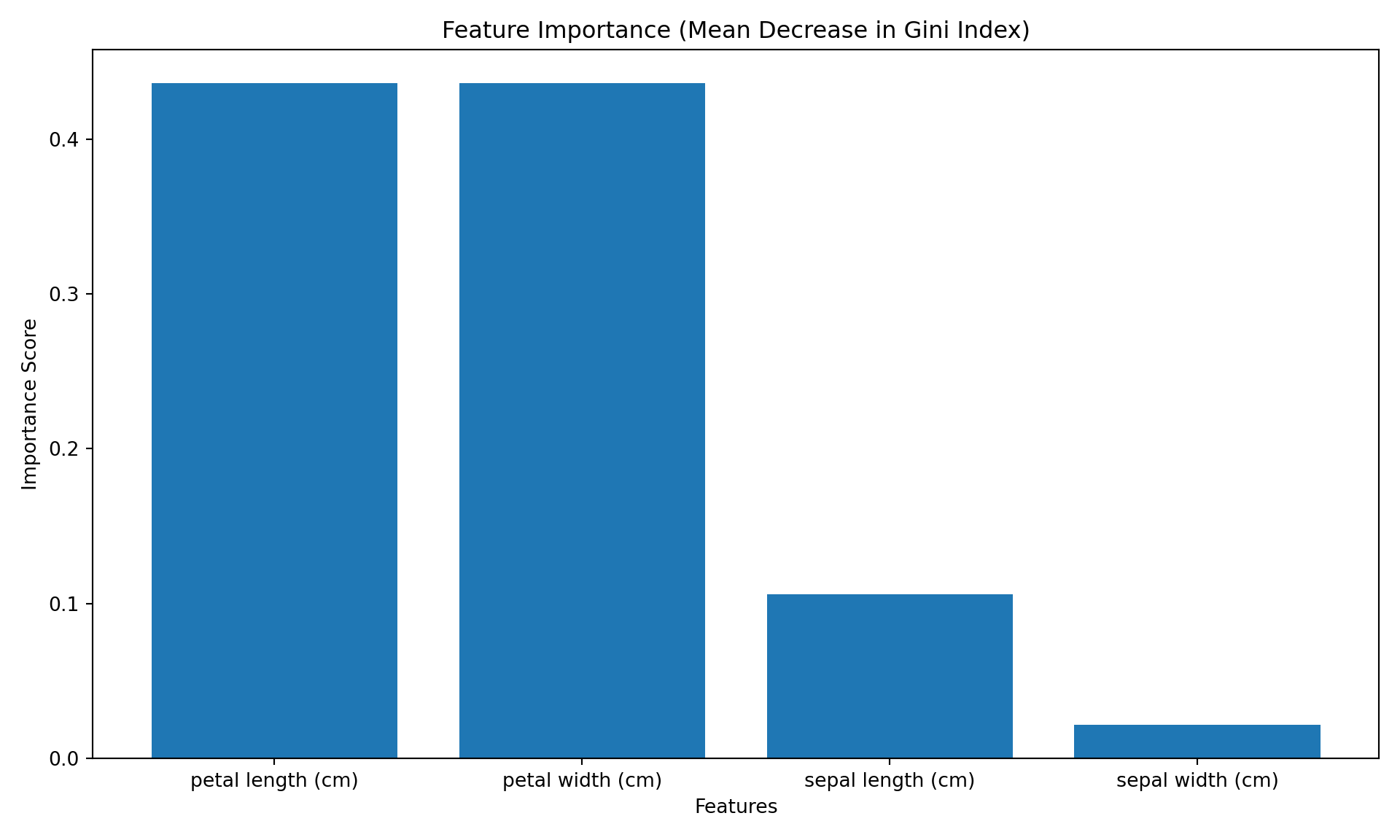
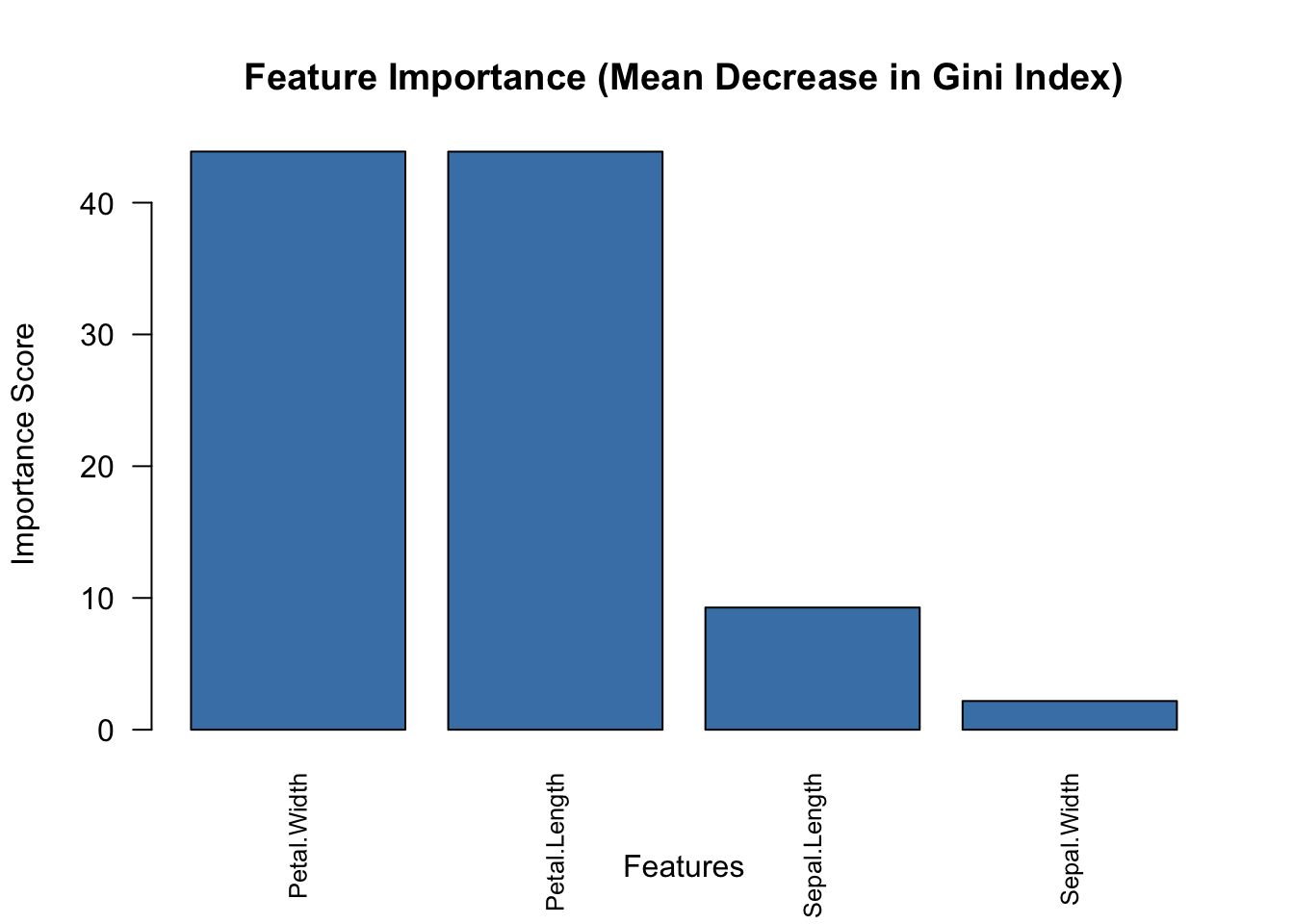
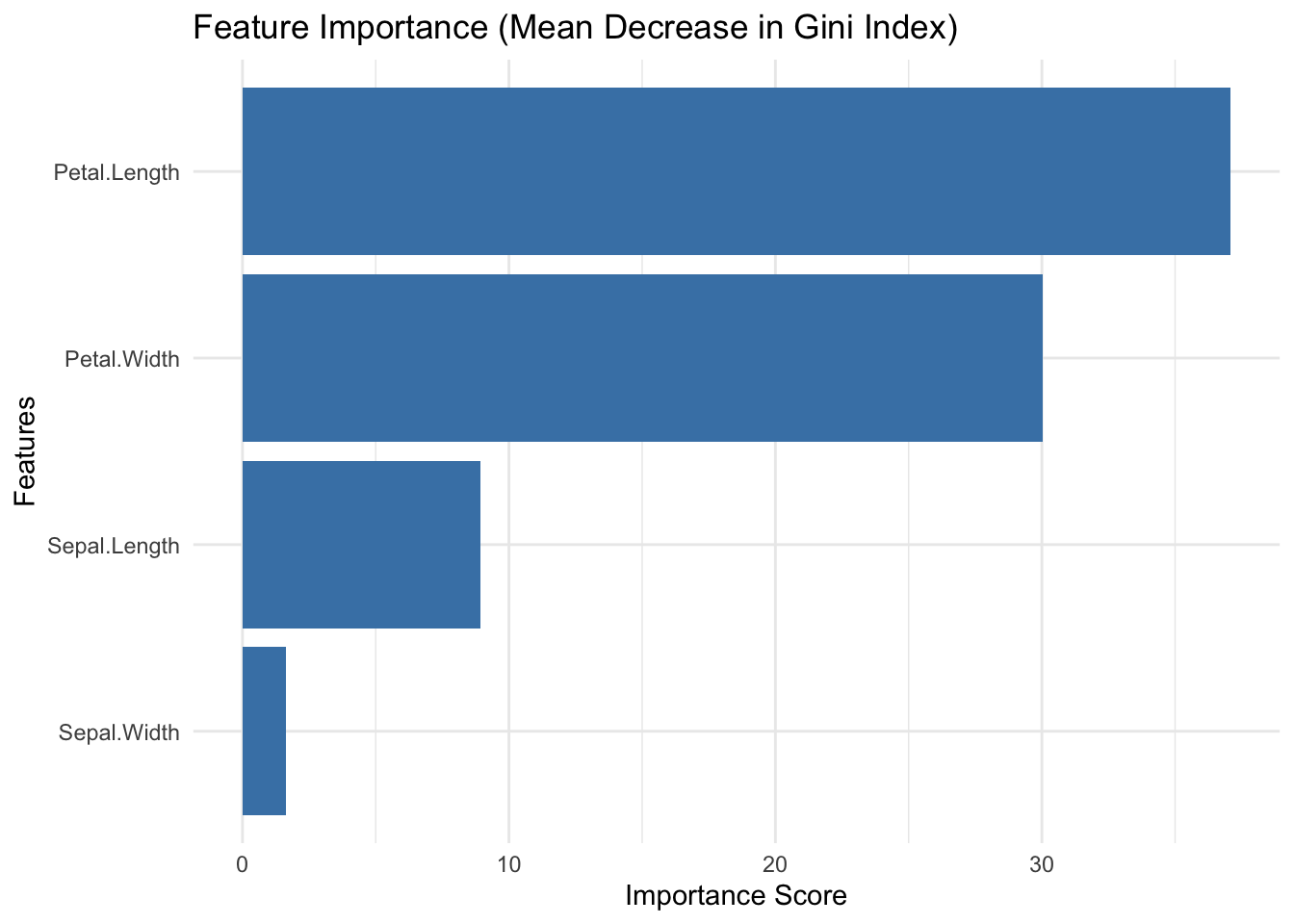
在随机森林模型中,mean decrease in gini index(也称为Gini重要性或基尼指数下降均值)用于衡量各特征对模型分类性能的贡献。
输出解释
- 每个柱状条的高度表示该特征对分类器性能的相对贡献,数值越大表示重要性越高。
- 特征可以按重要性从高到低排序,以便更直观地理解哪些变量在模型中最重要。
可以通过以下步骤绘制它:
Python 示例
假设使用的是 scikit-learn 的随机森林实现:
import matplotlib.pyplot as plt
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
# 加载数据集
data = load_iris()
X = data.data
y = data.target
feature_names = data.feature_names
# 训练随机森林模型
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X, y)
RandomForestClassifier(random_state=42)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
RandomForestClassifier(random_state=42)
# 获取 Gini 重要性
importances = rf.feature_importances_
# 对特征重要性排序
indices = np.argsort(importances)[::-1]
# 绘制柱状图
plt.figure(figsize=(10, 6))
plt.title("Feature Importance (Mean Decrease in Gini Index)")
plt.bar(range(X.shape[1]), importances[indices], align="center")
plt.xticks(range(X.shape[1]), [feature_names[i] for i in indices])
## ([<matplotlib.axis.XTick object at 0x1690cd650>, <matplotlib.axis.XTick object at 0x1690dc5d0>, <matplotlib.axis.XTick object at 0x1690dd110>, <matplotlib.axis.XTick object at 0x169142f90>], [Text(0, 0, 'petal length (cm)'), Text(1, 0, 'petal width (cm)'), Text(2, 0, 'sepal length (cm)'), Text(3, 0, 'sepal width (cm)')])
plt.xlabel("Features")
plt.ylabel("Importance Score")
plt.tight_layout()
plt.show()
R 示例
在 R 中,可以使用 randomForest 包来计算和绘制 Mean Decrease in Gini:
library(randomForest)
## randomForest 4.7-1.1
## Type rfNews() to see new features/changes/bug fixes.
# 加载示例数据集
data(iris)
set.seed(42)
# 训练随机森林模型
rf_model = randomForest(Species ~ ., data = iris, importance = TRUE)
# 提取 Gini 重要性
importance_data = importance(rf_model, type = 2)
feature_names = rownames(importance_data)
# 排序数据
sorted_indices = order(importance_data[, "MeanDecreaseGini"], decreasing = TRUE)
sorted_importance = importance_data[sorted_indices, "MeanDecreaseGini"]
sorted_feature_names = feature_names[sorted_indices]
# 绘制柱状图
barplot(sorted_importance,
names.arg = sorted_feature_names,
las = 2, col = "steelblue",
main = "Feature Importance (Mean Decrease in Gini Index)",
xlab = "Features", ylab = "Importance Score",
cex.names = 0.8) # 缩小标签字体以避免重叠
使用 tidymodels 框架
使用 tidymodels 框架,可以通过 vip(Variable Importance Plots)包来绘制随机森林模型的 Mean Decrease in Gini Index。以下是实现方法:
安装必要的包
确保安装以下包:
install.packages("tidymodels")
install.packages("vip")
示例代码
以下以 iris 数据集为例:
library(tidymodels)
## ── Attaching packages ────────────────────────────────────── tidymodels 1.1.1 ──
## ✔ broom 1.0.5 ✔ recipes 1.0.9
## ✔ dials 1.2.0 ✔ rsample 1.2.0
## ✔ dplyr 1.1.4 ✔ tibble 3.2.1
## ✔ ggplot2 3.5.1 ✔ tidyr 1.3.1
## ✔ infer 1.0.5 ✔ tune 1.1.2
## ✔ modeldata 1.2.0 ✔ workflows 1.1.3
## ✔ parsnip 1.1.1 ✔ workflowsets 1.0.1
## ✔ purrr 1.0.2 ✔ yardstick 1.2.0
## ── Conflicts ───────────────────────────────────────── tidymodels_conflicts() ──
## ✖ dplyr::combine() masks randomForest::combine()
## ✖ purrr::discard() masks scales::discard()
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()
## ✖ ggplot2::margin() masks randomForest::margin()
## ✖ recipes::step() masks stats::step()
## • Use tidymodels_prefer() to resolve common conflicts.
library(vip)
##
## Attaching package: 'vip'
## The following object is masked from 'package:utils':
##
## vi
# 加载数据集
data(iris)
# 定义数据拆分
set.seed(42)
iris_split = initial_split(iris, prop = 0.8)
iris_train = training(iris_split)
iris_test = testing(iris_split)
# 定义随机森林模型
rf_model = rand_forest(mtry = 2, trees = 100, min_n = 5) %>%
set_engine("ranger", importance = "impurity") %>%
set_mode("classification")
# 定义工作流
rf_workflow = workflow() %>%
add_model(rf_model) %>%
add_formula(Species ~ .)
# 训练模型
rf_fit = fit(rf_workflow, data = iris_train)
# 提取变量重要性并绘图
rf_fit %>%
extract_fit_parsnip() %>%
vip(geom = "col", aesthetics = list(fill = "steelblue")) +
labs(
title = "Feature Importance (Mean Decrease in Gini Index)",
x = "Features",
y = "Importance Score"
) +
theme_minimal()
输出解释
vip()函数会从模型中提取特征的重要性并绘制柱状图。- 这里使用了
ranger引擎,通过importance = "impurity"参数计算基尼指数下降。 geom = "col"绘制柱状图,并可以通过aesthetics自定义样式。
代码关键点
vip包:方便地绘制变量重要性。- 随机森林引擎:选择
ranger,因为它支持计算基尼重要性。 - 工作流:使用
tidymodels的工作流整合模型和预处理过程。