Posit公司在美国波士顿举办了Posit::conf(2025)大会。大会涵盖了数据科学、统计分析、机器学习和人工智能等多个领域。以下是大会中关于人工智能部分的精选内容摘要。
只有“人机结合"的数据科学才能所向披靡
标题:Making the most of artificial and human intelligence for data science (Hadley Wickham, Joe Cheng)
来源:https://www.youtube.com/watch?v=tSFHQWGyRzo
Posit公司的Hadley Wickham和Joe Cheng在这场主题演讲中,探讨了如何在数据科学中负责任地使用人工智能(AI)及大语言模型(LLM)。
Hadley Wickham 首先指出了AI的双面性:它既强大又存在风险。他强调,数据科学家应利用现有的编程技能来增强LLM,并通过紧密的人机回圈(human-in-the-loop)来引导AI。他介绍了Posit开发的R包ellmer,并解释了“工具(Tools)”这一核心概念,即通过函数让LLM与外部世界(如运行代码、获取数据)交互。

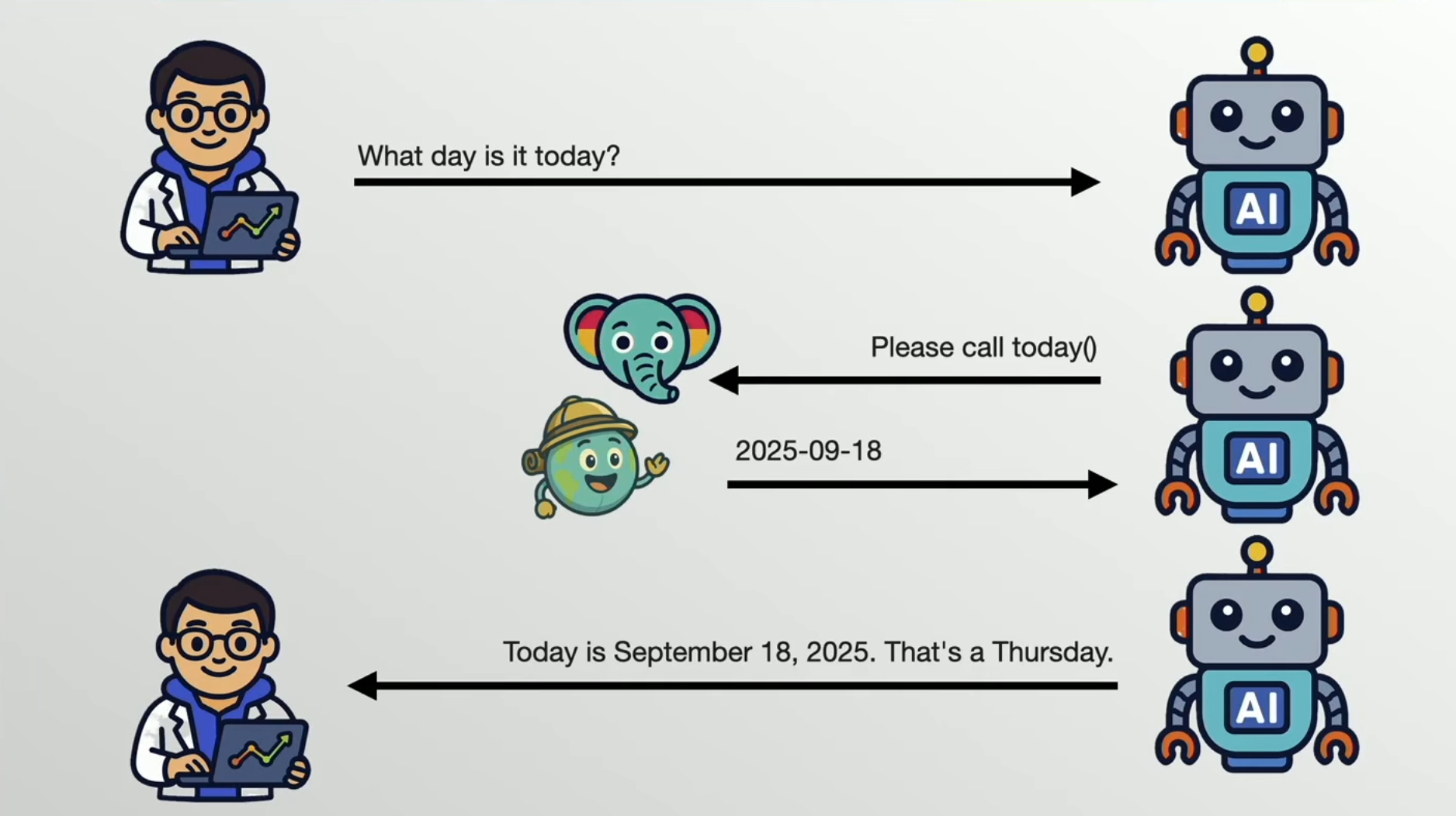
Hadley展示了几个实际应用:
- 结构化数据提取:从非结构化文本或图片中高效提取信息并整理成表格。
- QueryChat:在仪表盘中用自然语言生成SQL查询,以安全、可控的方式进行数据筛选。
- ggbot2:一个通过对话式交互创建
ggplot2图表的AI助手,展示了在专家引导下AI如何高效辅助数据可视化。
Joe Cheng 接着介绍了两款集成在Positron IDE中的AI代理(Agent):
- Positron Assistant:一个通用的编码助手,可以读写代码、解释错误和生成图表。
- Databot:一个专注于探索性数据分析(EDA)的工具。它通过“提问-生成代码-执行-观察结果-提出建议”的循环,与用户共同探索数据。Joe以一个实例说明,Databot能快速发现人类分析师都忽略的深层数据质量问题。
最后,Joe Cheng特别强调,这些AI工具是“能力增强器,而非替代品”,并打比方说“Databot不是救生圈”。他警告说,用户不能被动依赖AI,而必须作为积极的、具备专业知识的参与者,来引导、评估并纠正AI,其最终目标是加深对数据的理解,而不是简单地获取一个答案。
在 R 中评估模型的准确性
标题:Is that LLM feature any good? (Simon P. Couch, Posit) | posit::conf(2025)
来源:https://www.youtube.com/watch?v=HciRoc9TzMc
这篇演讲介绍了用于评估大型语言模型(LLM)应用的R语言工具包vitals。
演讲者Simon Couch首先以一个用R包Ellmer和Shinychat构建的会议日程聊天机器人为例,指出虽然现在构建LLM应用变得非常简单,但要将其从演示版推向生产环境,则需要可靠的测试和评估方法,而不能仅凭“感觉测试”。
他提出了两个核心观点:
- 应该做评估:为了快速迭代和提升AI应用质量,系统性的评估(evals)至关重要,就像软件开发中的单元测试一样。
- 能够做评估:如果你已经能用
Ellmer构建应用,那么使用vitals进行评估也同样简单,因为它是“即插即用”的。
vitals的评估流程包含三个核心部分:
- 数据集 (Dataset):包含用户输入和对应的标准答案/评分标准。
- 求解器 (Solver):直接使用你已有的
Ellmer应用。 - 评分器 (Scorer):通常利用另一个LLM来判断应用的输出是否符合标准。
通过vitals,开发者可以获得一个直观的日志查看器,它不仅能展示整体的准确率,还能让开发者深入分析每一个失败案例的具体原因,从而有效地调试和改进应用。总之,vitals为R用户提供了一套结构化、易于上手的方法来系统性地提升LLM应用的质量。
使用 LLM 进行数据清洗
标题:From messy to meaningful data: LLM-powered classification in R (Dylan Pieper) | posit::conf(2025)
来源:https://www.youtube.com/watch?v=Lo4vewuapI8
该视频介绍了如何在 R 语言中使用大语言模型(LLM)进行数据分类。主讲人演示了使用 elmer 包将文本、图片等非结构化数据转换为结构化的数据框。
核心观点和方法包括:
- 简化提示 (Prompting):与其编写复杂的提示语,不如专注于定义清晰的输出数据结构。
- 评估与验证:要求 LLM 返回其预测的“不确定性”或“置信度”分数,这个分数通常能反映模型的实际表现。
- 结合传统方法:LLM 在某些任务(如区分细微差异)上可能不如传统的机器学习模型。最佳实践是将 LLM 与传统模型结合使用,例如用 LLM 进行初步数据标注,或在生产中作为“第二意见”来发现不一致的结果并交由人工审核。
总之,LLM 是一个强大且易于使用的工具,但不应完全取代传统机器学习,而应作为辅助工具来提升数据处理工作流的效率和准确性。
基于 AWS 云服务开发企业级 Agent 应用
标题:Building Agentic AI applications with Positron and AWS Strands Agents (Greg Headley & Shun Mao, AWS)
来源:https://www.youtube.com/watch?v=jLyudeHXjJc
这篇视频介绍了AWS与Posit如何合作,帮助开发者和数据科学家构建从开发到生产级别的AI智能体(Agent)应用。
核心内容围绕AWS最新发布的开源SDK——Strands Agents展开。其主要特点是:
- 简化开发:通过整合提示(Prompt)、**大语言模型(LLM)和工具(Tools)**三大核心组件,开发者仅需少量代码即可构建功能强大的智能体。
- 模型选择灵活:支持包括Amazon Bedrock、本地部署模型(通过Ollama)及OpenAI在内的多种大语言模型。
- 强大的工具集成:
- 提供计算器、文件操作等内置工具。
- 亮点功能:能轻松将任何现有的Python函数(只需添加描述性文档字符串)转换为智能体可调用的工具,对数据科学家极其友好。
- 支持调用第三方API(如网页搜索)和连接企业知识库(如Pinecone向量数据库)。
视频最后在Positron环境中进行了现场演示,展示了如何逐步为一个智能体添加计算器、自定义Python函数、API调用等多种工具,并最终将其打包成一个可交互的Streamlit应用,证明了整个过程的简便与高效。